We propose an efficient encoder-decoder architecture for neural source separation, called spectral feature compression (SFC), which compresses the input using a single sequence modeling module, making it both input-adaptive and parameter-efficient.
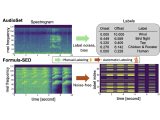
A novel framework for pre-training environmental sound analysis models by utilizing parametrically synthesized acoustic signals using formula-driven methods.
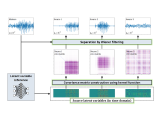
This paper revisits single-channel audio source separation based on a probabilistic generative model of a mixture signal defined in the continuous time domain.
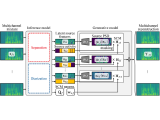
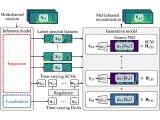
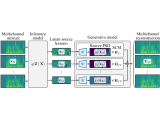
This paper presents an unsupervised multichannel method that can separate moving sound sources based on an amortized variational inference (AVI) of joint separation and localization.
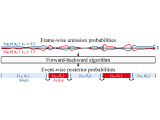
This paper describes a neural blind source separation (BSS) method based on amortized variational inference (AVI) of a non-linear generative model of mixture signals.