This paper presents a neural method for distant speech recognition (DSR) that jointly separates and diarizes speech mixtures without supervision by isolated signals. A standard separation method for multi-talker DSR is a statistical multichannel method called guided source separation (GSS). While GSS does not require signal-level supervision, it relies on speaker diarization results to handle unknown numbers of active speakers. To overcome this limitation, we introduce and train a neural inference model in a weakly-supervised manner, employing the objective function of a statistical separation method. This training requires only multichannel mixtures and their temporal annotations of speaker activities. In contrast to GSS, once trained, the model can jointly separate and diarize speech mixtures without any auxiliary information. The experimental results with the AMI corpus show that our method outperforms GSS with oracle diarization results regarding word error rates.
Our joint separation and diarization model.
Title
Neural Blind Source Separation and Diarization for Distant Speech Recognition
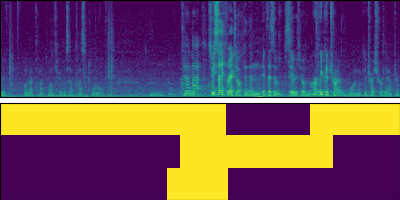
We demonstrate that our model trained on the AMI English corpus can work robustly even for the out-of-domain condition of Japanese conversations.
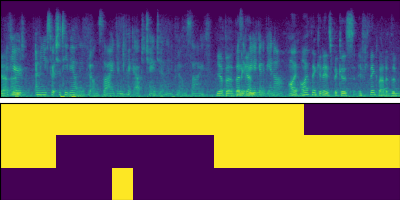
English conversation
Japanese conversation
Separation and diarization results for mixtures in the AMI corpus #
We show the separation and diarization results for the mixtures in the eval set of the AMI corpus.
Note that these signals are different from those used for the WER evaluation in the paper. The WER was calculated for crops of mixture signals, each having a minimum length of 10 seconds and a target utterance at its center.