Onset-and-Offset-Aware Sound Event Detection via Differentiable Frame-to-Event Mapping
This paper presents a sound event detection (SED) method that handles sound event boundaries in a statistically principled manner. A typical approach to SED is to train a deep neural network (DNN) in a supervised manner such that the model predicts frame-wise event activities. Since the predicted activities often contain fine insertion and deletion errors due to their temporal fluctuations, post-processing has been applied to obtain more accurate onset and offset boundaries. Existing postprocessing methods are, however, non-differentiable and prohibit end-to-end (E2E) training. In this paper, we propose an E2E detection method based on a probabilistic formulation of sound event sequences called a hidden semi-Markov model (HSMM). The HSMM is utilized to transform frame-wise features predicted by a DNN into posterior probabilities of sound events represented by their class labels and temporal boundaries. We jointly train the DNN and HSMM in a supervised E2E manner by maximizing the event-wise posterior probabilities of the HSMM. This objective is a differentiable function thanks to the forward-backward algorithm of the HSMM. Experimental results with real recordings show that our method outperforms baseline systems with standard post-processing methods.
Overview of the frame-to-event mapping.
Title
Onset-and-Offset-Aware Sound Event Detection via Differentiable Frame-to-Event Mapping
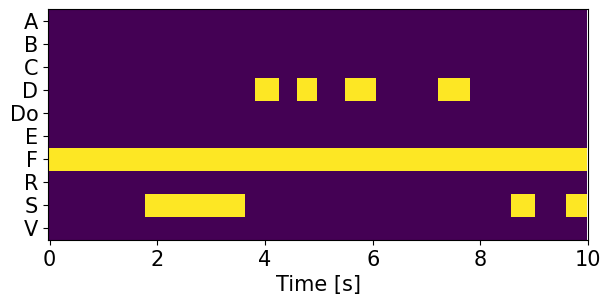
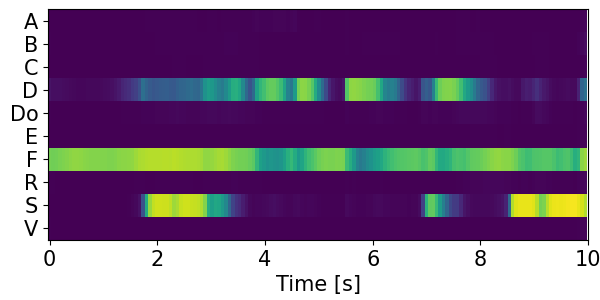
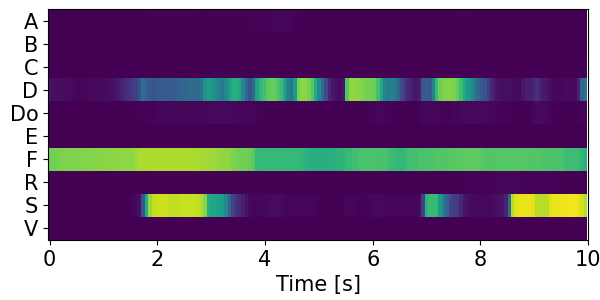
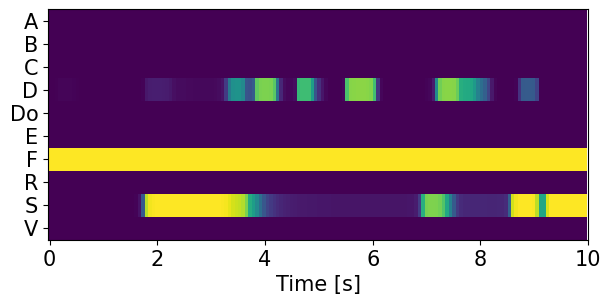
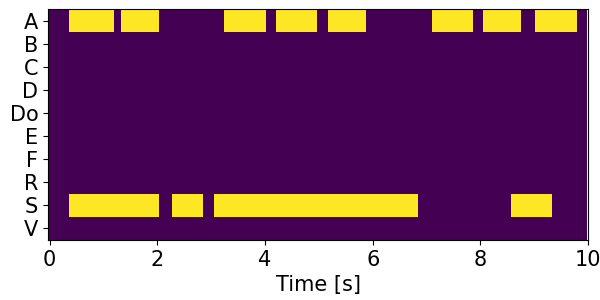
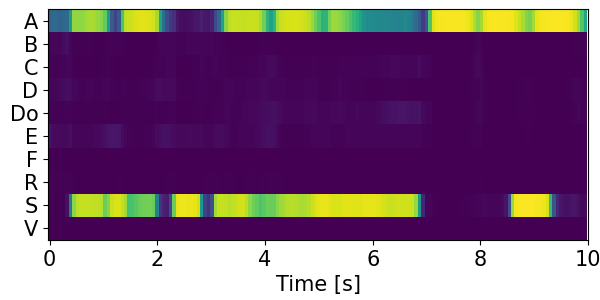
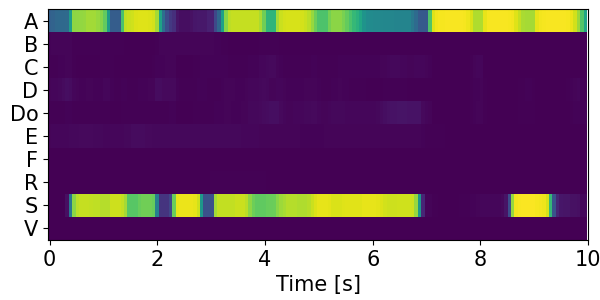
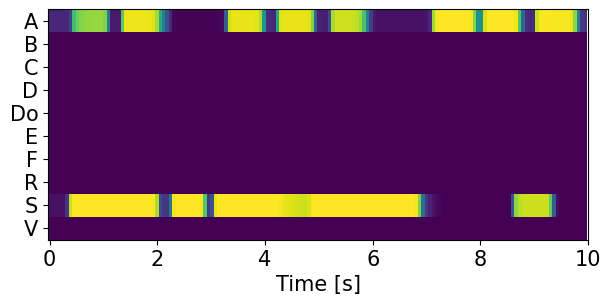
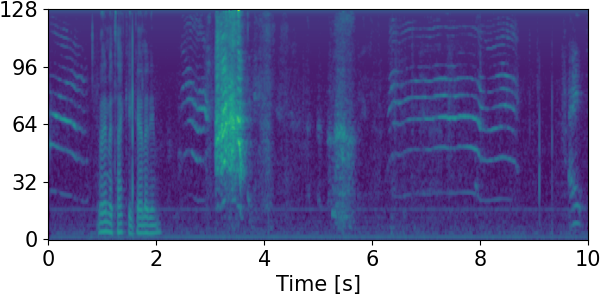
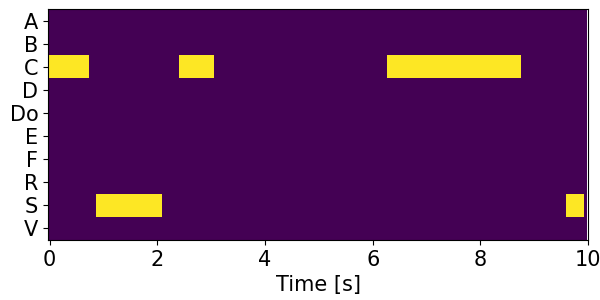
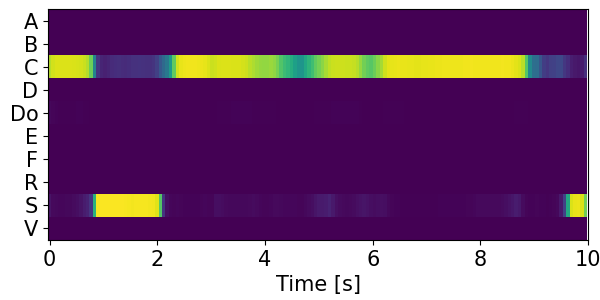
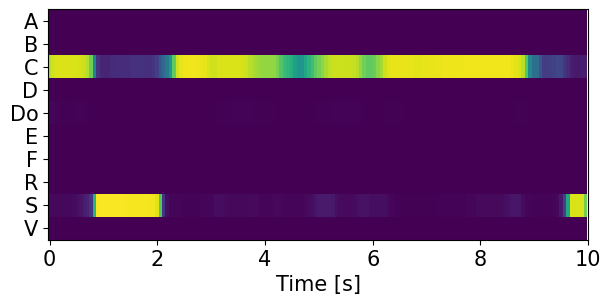
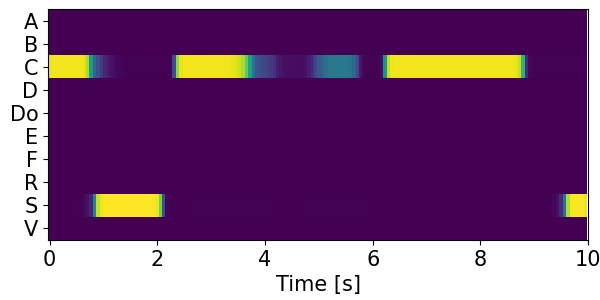
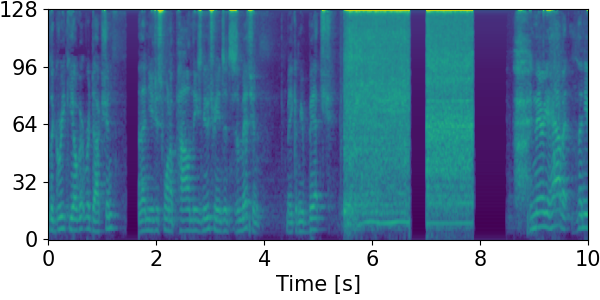
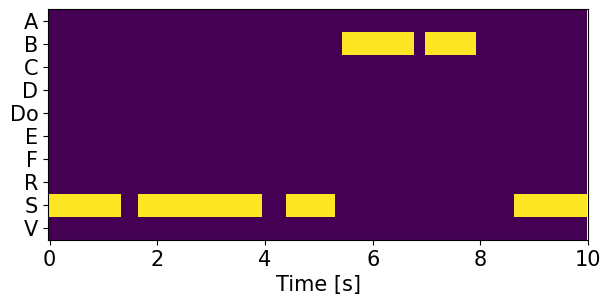
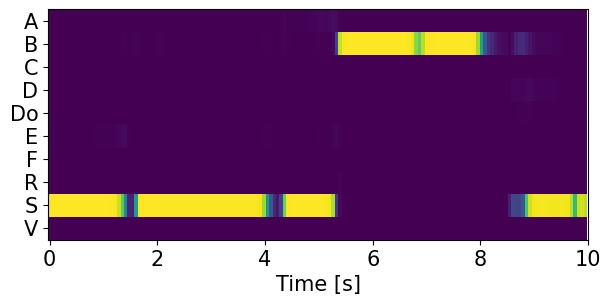
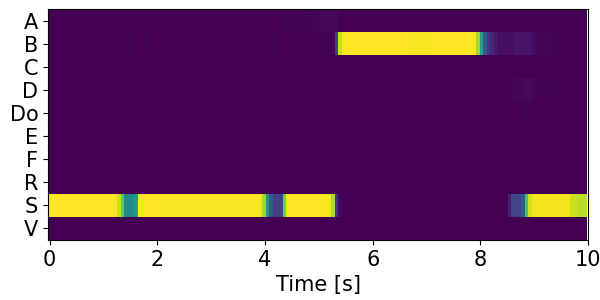
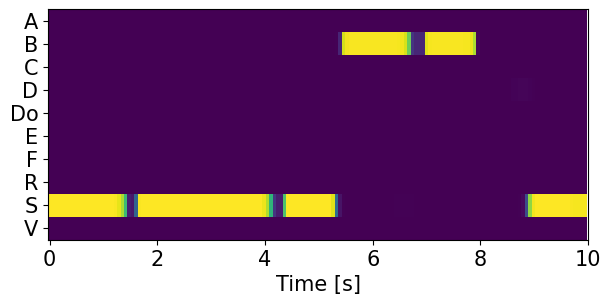
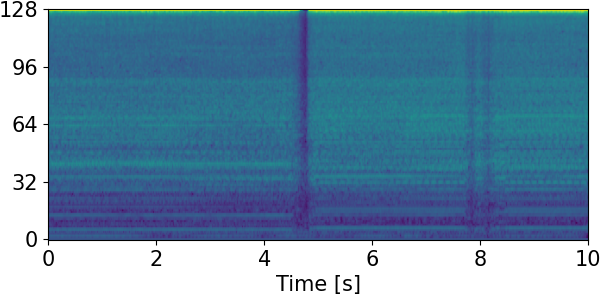
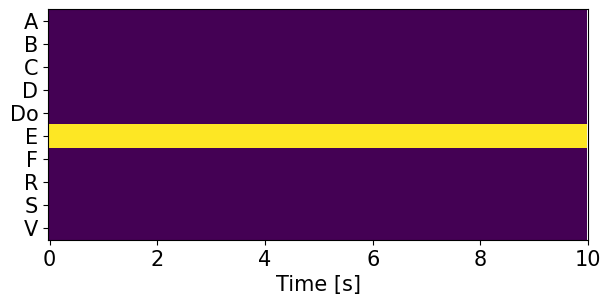
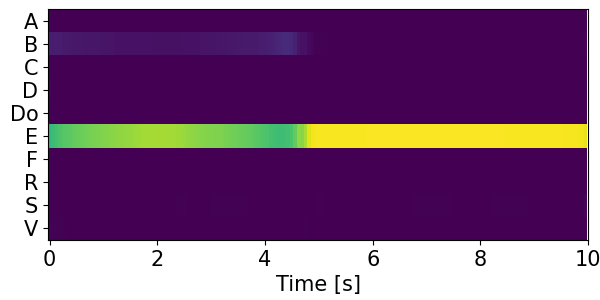
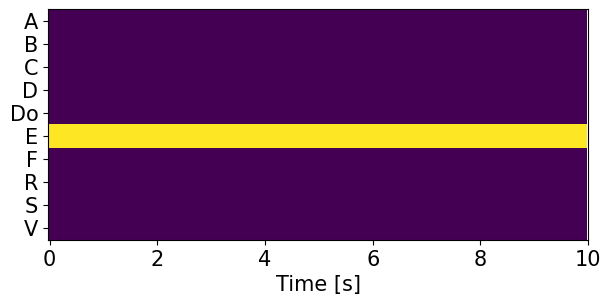
Detection results for mixtures in the DESED dataset #
We show the detection results for the mixtures in the eval set of the DESED dataset.
Clips are annotated with 10 types of sound events: alarm/bell/ringing (A), blender (B), cat (C), dishes (Di), dog (Do), electric shaver/toothbrush (E), frying (F), running water (R), speech (S), and vacuum cleaner (V).